文本输入——》张量输入
BPE
初始化 每个词独立 token
统计词频
合并高频词对新token
更新词表 高频词变为单独token
重复统计 和更新 进行压缩 去重
Tokenizer
Encode:根据词表 文本转 token-id
Decode:将token-id还原成文本
transformers
pip install transformers
文本嵌入
将tokens 转换为向量(张量)
独热编码 one-hot
有就是1 无就是0 维度和整体大小有关
Word Embedding
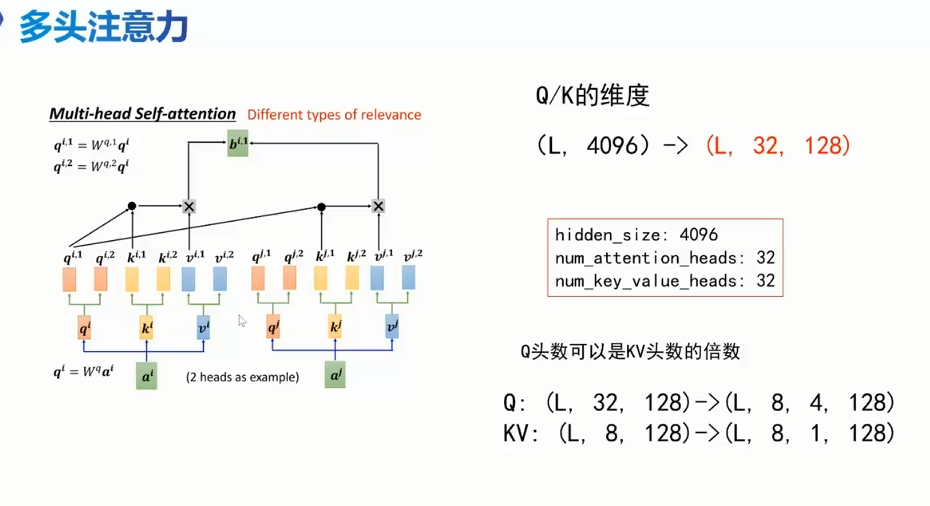
hidden_size: 4096 意味着每一层都是固定维度
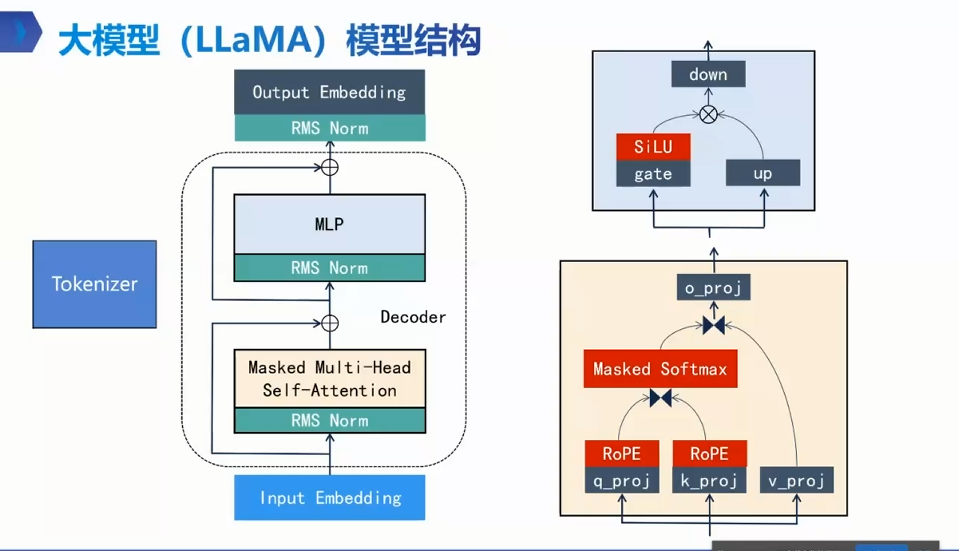
Transformer架构
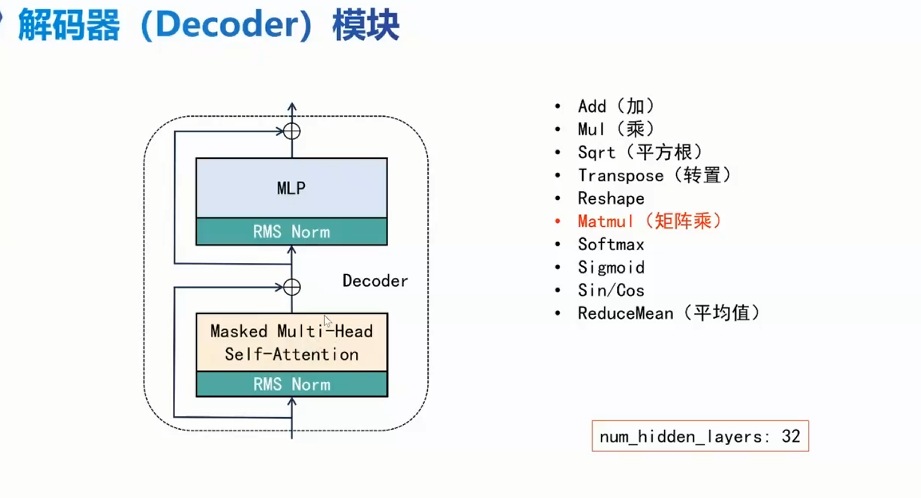
 RMS Norm
层归一化
防止梯度爆炸
gi权重
RMS Norm
层归一化
防止梯度爆炸
gi权重
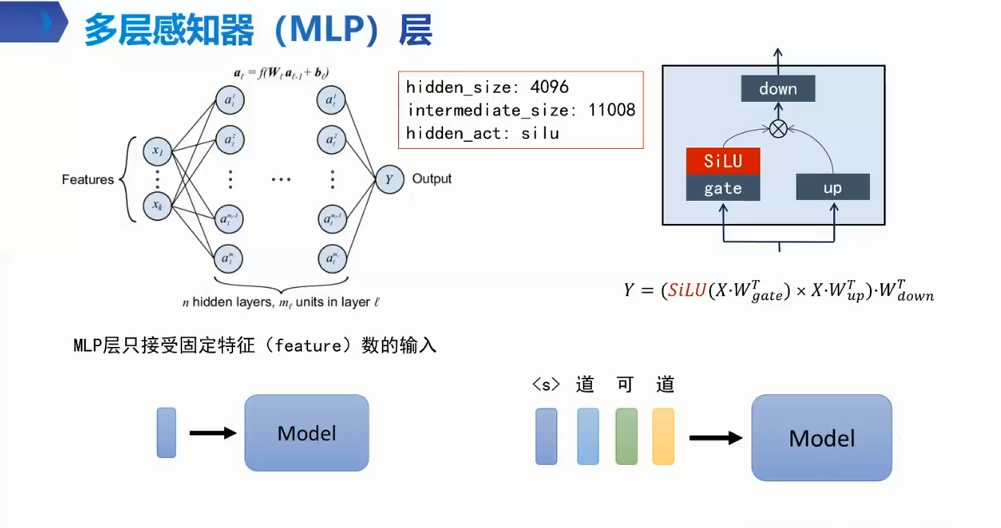
MLP hidden_size: 4096
intermediate_size: 11008 hidden_act: silu
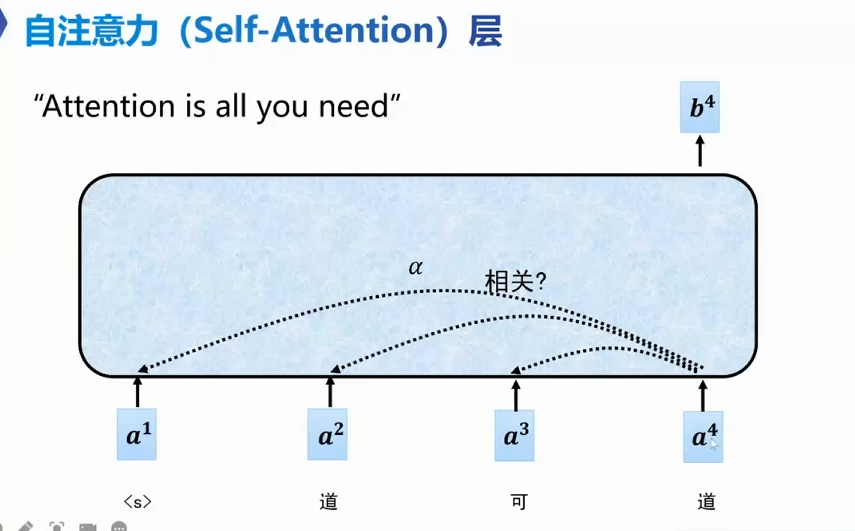
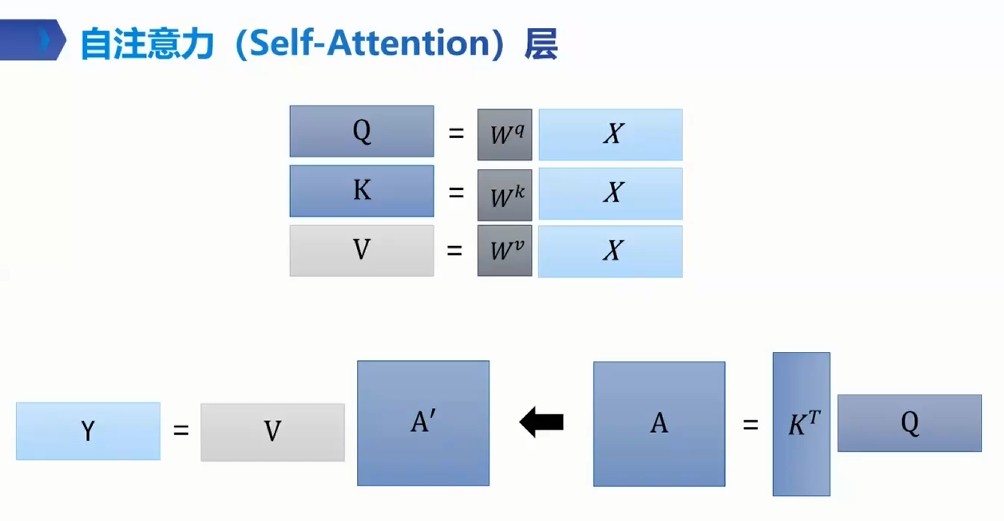
Self-Attention
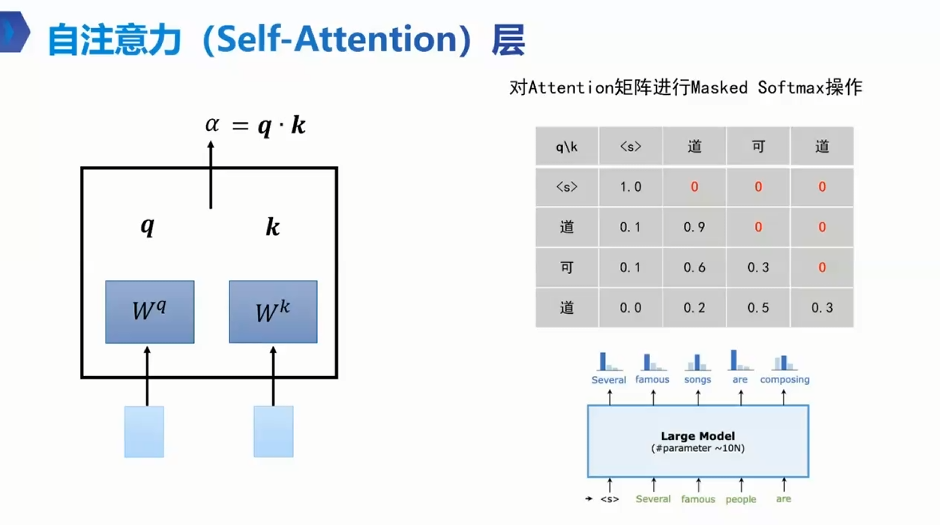
α= q·k
token 乘 q k 得 wq wk 两两之间 求 后q点乘前k α 一个数 decode only 每个词只向前考虑 看前 推测后 α 做归一化 相当于前文的百分之多少
整体 qk矩阵乘得 A A做mask softmak 得A丿 乘V 得输出
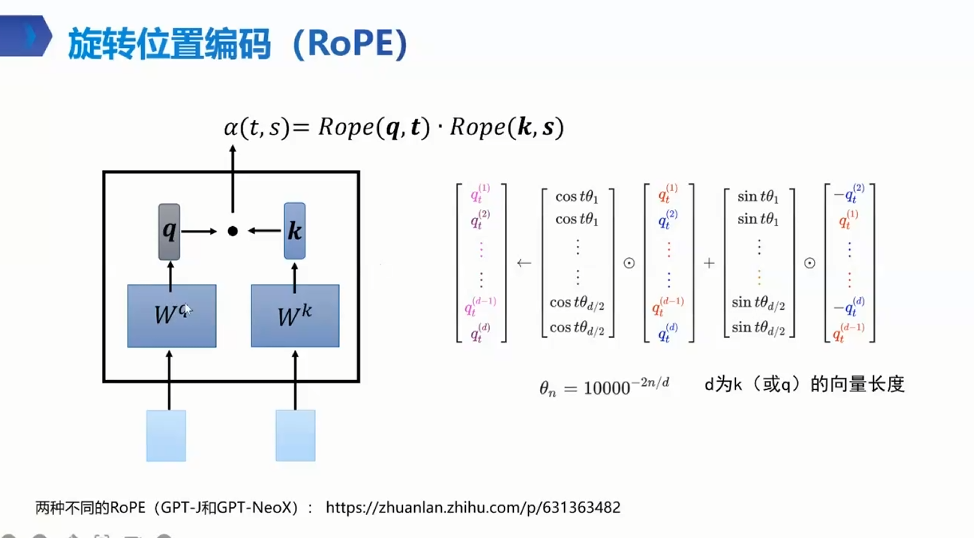
歧义点: 一行行,行行行 这怎么算 两token 注意力 qk点积 α 注意力没位置就会有问题
旋转位置编码(RoPE)
o_proj 权重矩阵转维度
多头注意力 MHA
解码器
输出嵌入层 hiden_size,vocab_size 词表里的概率分布
标准llama模型配置







评论(0)
暂无评论