

1. 项目架构概览
🌟 用一个通俗的类比来理解vLLM
想象一下高速公路上的智能调度系统:
-
• 收费站(Entrypoints):用户的请求从这里进入系统,就像车辆进入高速公路 -
• 交通指挥中心(Scheduler):智能地决定哪些车先走、怎么组队、走哪条车道,让整体通行效率最高 -
• 分页停车场(PagedAttention):这是vLLM的”独门绝技”!就像操作系统的虚拟内存,把KV Cache分成小块灵活管理,再也不用担心”停车位”不够用了 -
• 高速车道(Workers):实际的GPU计算单元,负责”跑模型” -
• 调度引擎(LLM Engine):整个系统的大脑,协调一切
这不是一个简单的”请求-响应”系统,而是一个持续优化吞吐量的智能调度系统。它的设计哲学是:让GPU始终处于高负载状态,绝不浪费一个计算周期。
🎯 核心设计特征
vLLM的架构有几个”与众不同”的闪光点:
-
1. PagedAttention – 内存管理的革命 📄这是vLLM最核心的创新!传统的LLM推理会预先分配固定大小的内存给KV Cache,就像你订酒店必须订整个房间,哪怕只住一晚。而PagedAttention就像Airbnb,按需分配”房间”(内存块),极大提高了内存利用率。技术要点: -
• KV Cache被分成固定大小的块(类似操作系统的分页) -
• 支持内存共享(Prefix Caching),相同的prompt前缀可以共享KV Cache -
• 显著减少内存碎片,提升吞吐量
-
-
2. Continuous Batching – 永不停歇的批处理 ⚡不像传统的静态批处理(等一批请求都结束了再处理下一批),vLLM采用连续批处理: -
• 一个请求完成了?立刻用新请求补上它的位置! -
• GPU永远在满负荷工作,不会因为某个长请求而闲置 -
• 就像餐厅的”翻台率”优化,座位永远不空着
-
-
3. CUDA Graph优化 – 减少启动开销 🚄把重复的计算图”录制”下来,之后直接回放,减少Python和CUDA之间的交互开销。 -
4. 多样化的量化支持 🎨支持GPTQ、AWQ、INT4/8、FP8等多种量化方式,让你在精度和速度之间灵活权衡。
vLLM采用的是分层的执行器-工作器架构,清晰地分离了调度逻辑和执行逻辑:
用户请求
↓
Entrypoints (LLM / AsyncLLMEngine / OpenAI-compatible API)
↓
LLMEngine (核心引擎:调度、内存管理、输出处理)
↓
Executor (执行器:管理分布式工作器)
↓
Workers (工作器:在GPU上实际运行模型)
↓
CUDA/HIP Kernels (高度优化的底层内核)
每一层都有明确的职责边界,这种设计让系统既灵活(容易扩展新特性)又高效(每层都针对性优化)。
🆚 与其他推理引擎的对比
vLLM相比其他推理引擎(如TensorRT-LLM、SGLang、LMDeploy)的主要优势:
-
• 开箱即用:无需复杂的模型转换,直接支持HuggingFace模型 -
• 内存效率:PagedAttention带来的内存利用率提升显著 -
• 社区活跃:已成为PyTorch生态的一部分,更新快,问题响应及时 -
• 灵活性高:支持多种硬件(NVIDIA、AMD、Intel、TPU)和多种部署模式
vLLM的”人设”:一个追求极致性能、同时保持易用性的”实用主义者”。
🌐 技术栈分析
让我们看看vLLM的”装备清单”:
核心依赖:
-
• PyTorch 2.6.0:深度学习框架基础,负责模型加载和张量操作 -
• Python 3.9-3.12:主要编程语言 -
• C++/CUDA/HIP:高性能内核实现(csrc目录下有大量CUDA代码) -
• CMake:构建系统,负责编译C++/CUDA扩展
关键库:
-
• xformers:提供优化的Attention实现 -
• FlashAttention/FlashInfer:高性能Attention内核 -
• Ray:分布式计算框架,支持流水线并行 -
• Numba:用于N-gram推测解码
为什么选择这些技术?
-
1. PyTorch而非TensorFlow:因为HuggingFace生态都是基于PyTorch -
2. 自研CUDA内核:通用框架难以达到极致性能,vLLM在关键路径上自己写内核 -
3. Ray做分布式:成熟、灵活,支持复杂的并行策略 -
4. CMake构建:跨平台,灵活配置不同硬件后端
🔗 外部系统集成
vLLM作为推理引擎,需要与多种外部系统交互:
上游集成:
-
• HuggingFace Hub:直接加载模型和分词器 -
• OpenAI API:提供兼容的API接口(vllm.entrypoints.openai) -
• Prometheus:暴露监控指标
下游依赖:
-
• GPU驱动:CUDA(NVIDIA)、ROCm(AMD)、oneAPI(Intel) -
• 存储系统:可选的tensorizer、fastsafetensors用于快速模型加载
配置管理:
-
• 通过环境变量( VLLM_*)和命令行参数配置 -
• 支持YAML配置文件(用于serving模式)
📊 架构流程描述
让我们跟踪一个用户请求的完整生命周期:
场景:用户通过LLM类做离线批量推理
from vllm import LLM, SamplingParamsllm = LLM(model=”facebook/opt-125m”)
outputs = llm.generate([“Hello world”], SamplingParams(max_tokens=20))
流程图:
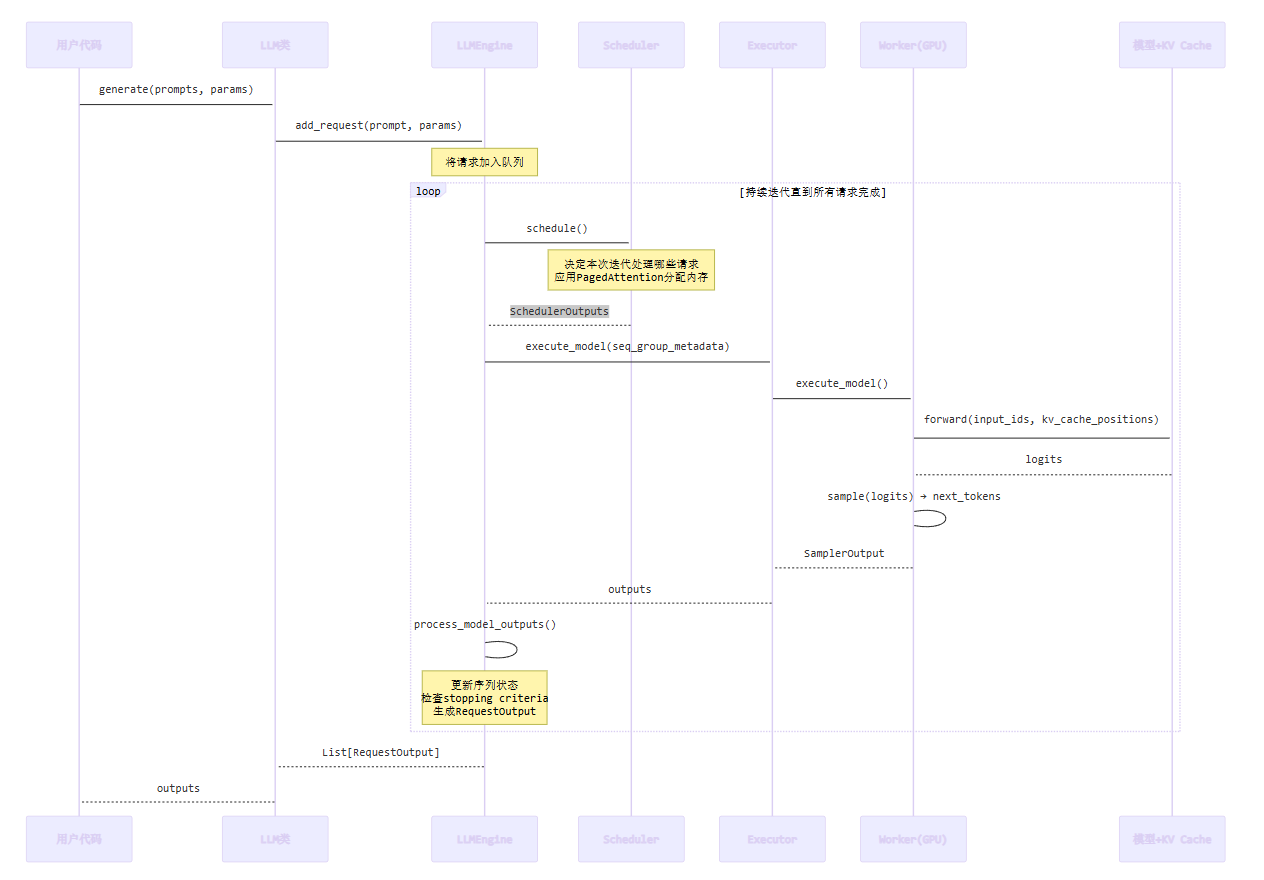
关键步骤解析:
-
1. 请求接收 (LLM.generate) -
• 用户调用 generate()方法 -
• 内部调用 LLMEngine.add_request()将请求加入待处理队列 -
• 每个请求被封装成 SequenceGroup对象
-
-
2. 调度 (Scheduler.schedule) -
• 决定本次迭代处理哪些请求(running, swapped, waiting) -
• 使用PagedAttention算法为每个序列分配KV Cache块 -
• 生成 SequenceGroupMetadata(包含位置信息、块映射表等) -
• 返回 SchedulerOutputs
-
-
3. 模型执行 (Worker.execute_model) -
• 准备输入张量(input_ids, positions) -
• 准备KV Cache映射关系 -
• 调用模型的 forward()方法 -
• 使用高度优化的Attention内核计算 -
• 采样得到下一个token
-
-
4. 输出处理 (Engine.process_model_outputs) -
• 更新每个序列的状态(添加新token) -
• 检查是否满足停止条件(EOS、max_tokens等) -
• 对于完成的序列,生成 RequestOutput返回给用户 -
• 对于未完成的序列,继续下一轮迭代
-
-
5. 循环迭代 -
• 这个过程会持续循环,直到所有请求都完成 -
• 每次迭代可能处理不同的请求组合(Continuous Batching的体现)
-
核心文件实现索引:
-
• 用户入口: vllm/entrypoints/llm.py(LLM类) -
• 引擎核心: vllm/engine/llm_engine.py(LLMEngine类) -
• 调度器: vllm/core/scheduler.py(Scheduler类) -
• 执行器: vllm/executor/gpu_executor.py(GPUExecutor类) -
• 工作器: vllm/worker/worker.py(Worker类) -
• 模型运行器: vllm/worker/model_runner.py(ModelRunner类) -
• Attention实现: vllm/attention/backends/(各种后端实现) -
• CUDA内核: csrc/attention/(高性能内核代码)

评论(0)
暂无评论